I’ve recently been playing a really cool video game: Vainglory. This is described as a MOBA which I must admit I had never heard off until this year when my students mentioned it to me, but basically it’s an online multi player game in which players form two teams of 6 heroes and fight each other. The choice of the heroes is very important as the composition of a team can make or break a match. This seems to have a bit of a cult following (so no doubt just like for my post about clash of clans I might annoy people again) and there is a great wiki that gives guides for the play of each player. In this post I’ll describe using Python to scrape that wiki to get data that feeds in to a game theoretic model which I then analyse using Sagemath to give some insight about the choice of hero.
Here’s the map where this all takes place:

So first of all, my understanding is that there are generally three types of playing strategy in the game:
- Lane: a hero that occupies and tries to take over the main route between the two bases.
- Jungle: a hero that goes ‘off road’ and kills monsters, gets gold etc…
- Roam: a hero who roams in between the two and whose main job is to support the other two players.
My personal strategy is to pick a roamer/protector: Ardan (pic below),

I generally help out the jungler in my team and try my best to not be a liability by dying.
The wiki has a bunch of information for players. If you google something like ‘vainglory best strategy’ it comes up. If you look up each hero you get a collection of guides ranked by votes each with all sorts of information which includes the where each and every other hero sits on a threat level (from 1 to 10). Here is the threat meter for Ardan from the top guide:

So from that guide it looks like if your opponent is going to be isolated with Ardan then you should pick HERO. In some guides the threat meter does not list all the heros. This is particularly important as it’s these threat meters that I’ve used as a source of data for how good a given hero is against other heros.
This is where the keener player/reader will note that the threat meter only describes the threat to a single player and not any information about how this fits within a team dynamic. This is an important admission on my part: as indicated by the title of this post aims to use data and game theory to give an indication as to how to choose heros for isolated combat against other single heros. So one application of this is choosing a jungler/laner when you expect to go up against another team that is playing a single jungler/laner.
Scraping the data
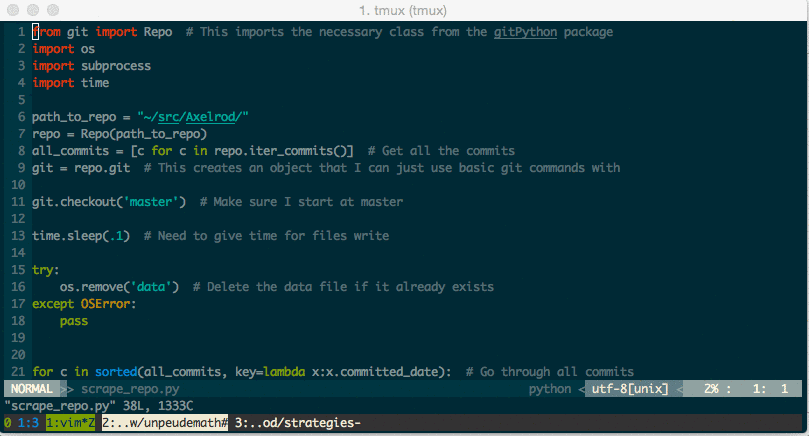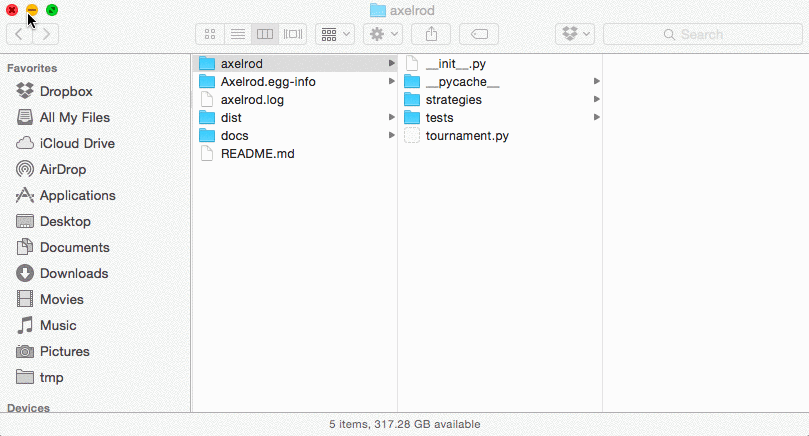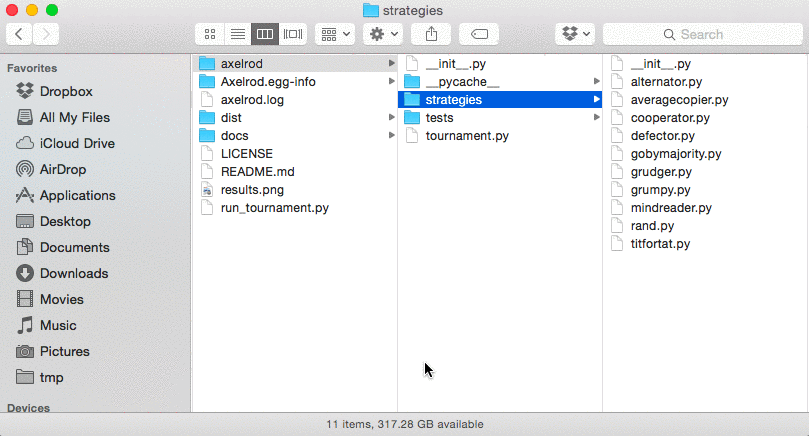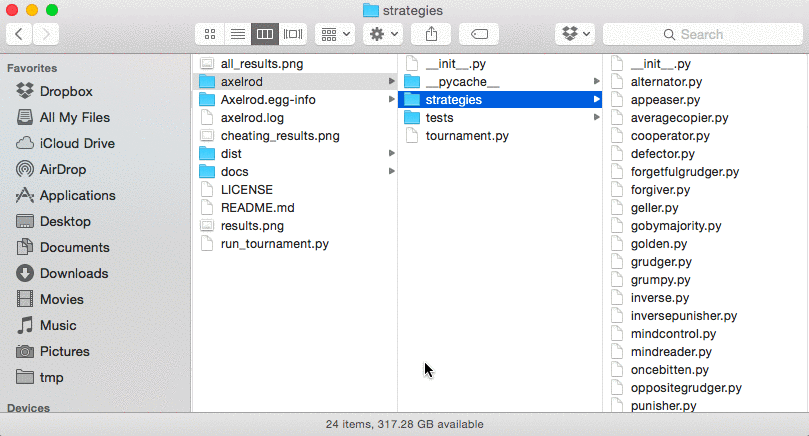
First things first: I used Python with the BeautifulSoup and requests library. For example here is how I got the lists of all the heroes (and the url to their own respective page on the wiki):
>>>page=requests.get('http://www.vaingloryfire.com/vainglory/wiki/heroes')>>>soup=BeautifulSoup(page.text,'html.parser')>>>root='/vainglory/wiki/heroes'>>>urls=[link.get('href')forlinkinsoup.find_all('a')]>>>heroes={url[len(root)+1:]:urlforurlinurls[2:]ifurl.startswith(root+'/')}>>>delheroes['skye']# Removing skye as she is brand new{u'adagio':u'/vainglory/wiki/heroes/adagio',u'ardan':u'/vainglory/wiki/heroes/ardan',u'catherine':u'/vainglory/wiki/heroes/catherine',u'celeste':u'/vainglory/wiki/heroes/celeste',u'fortress':u'/vainglory/wiki/heroes/fortress',u'glaive':u'/vainglory/wiki/heroes/glaive',u'joule':u'/vainglory/wiki/heroes/joule',u'koshka':u'/vainglory/wiki/heroes/koshka',u'krul':u'/vainglory/wiki/heroes/krul',u'petal':u'/vainglory/wiki/heroes/petal',u'ringo':u'/vainglory/wiki/heroes/ringo',u'rona':u'/vainglory/wiki/heroes/rona',u'saw':u'/vainglory/wiki/heroes/saw',u'skaarf':u'/vainglory/wiki/heroes/skaarf',u'taka':u'/vainglory/wiki/heroes/taka',u'vox':u'/vainglory/wiki/heroes/vox'}(Note there that I’m removing a brand new hero: Skye as she was released pretty much at the same time as I was writing this post.)
You can see the JuPyTer notebook which shows the code. The main technicality is that I only scraped guides from the front page for each hero. As I’ll describe later, I ran my analysis taking the average threats for a variety of cases: only taking the first guide, only taking the first 2 guides, the first 3 guides etc…
Here for example is the threats data for Adagio if you only look at this first guide:
[0,0,0,0,0,0,4,0,0,0,4,0,0,7,0,0]Cross referencing that with the order given by the list of heroes above we see that Skaarf ranks a 7 on the threat meter to Adagio, and Ringo and Joule a 4. All the 0s are what I’ve decided to do when a threat meter does not include a given hero: indicating that that hero is not a threat to that hero. I don’t really like this as a solution but it’s probably the least worst way to deal with it (if anyone has a better way of handling this please let me know in the comments).
Here is the threats data for Krul:
[6,3,4,3,6,4,3,7,5,5,4,0,6,6,5,0]We see that in this case the only heroes that pose no threat to Krul are Fortress and Rona. Thus if your opponent is playing those heroes Krul is a best response.
As will be described in the next section, we need to build up a matrix of these rows which basically shows how well a given hero does against others. Here is the matrix of this when considering the row players and taking the opposite of the threats when using just the top guide:
If you consider a column (that corresponds to a hero) of that matrix, the row player aims to find the row that gives the highest score, which because we’ve taken the opposite of the threat score corresponds to minimising the threat posed by the column hero. This is in essence a risk averse approach, at the very end I’ll comment on what happens to the results when players aim to maximise the threat they pose.
Now that I’ve described the data (you can find all the data written to specific csv files here) I’ll go on to talk about the game theory used to try and see what the equilibrium choice of strategies should/could be.
Game theoretic analysis
All of this has been done using Sagemath, a great open source mathematics package that offers an alternative to Maple, Mathematica etc…
If you’re not familiar with game theory, this video might help (it shows the basics of game theory and how Sagemath can be used to find Nash equilibria):
Before talking about equilibria let’s just look at best response dynamics.
Using Sage we can first of all build up the normal form game for a given number of guides:
sage:defbuild_game(row_player_file,col_player_file):....:"""Import the bi matrices and create the game object"""....:bi_matrices=[]....:forflein[row_player_file,col_player_file]:....:f=open(fle,'r')....:csvrdr=csv.reader(f)....:bi_matrices.append(-matrix([[float(ele)foreleinrow]forrowincsvrdr]))....:f.close()....:....:returnNormalFormGame(bi_matrices)sage:g=build_game("A-01.csv","B-01.csv")Using this and the best_response method on Sagemath NormalFormGames we can
build up all the best responses (according to a given number of guides) go each
player. The cool thing is that Sagemath has some awesome graph theory written
in there so we can transform that in to a nice picture (again: all the code for
this can be found
here):

That plot confirms what we have seen earlier, we see that Krul is a best response to Fortress or Rona. Sadly, because there are so many zeros when just using the first guide, there are a bunch of heros that are not considered a threat to any of the players so they have multiple best responses and our graph is messy.
Here is the best response graph when taking the mean threats over all front page guides:

Note that Game Theory assumes that everyone know that everyone know that everyone knows… all this. So for example if two players both player Adagio we are at an equilibrium. However if one player plays Saw then the graph indicates that the opponent should play Koshka, which means that the first player should then deviate and play Fortress which is then also an equilibrium (bot players are playing best responses to each other).
From here on I will continue the analysis using the average utility from all the guides (I’ll come back to this at the end).
So we can use Sagemath to compute all the equilibria for us. A Nash equilibria need not be a pure strategy and so will at times be a probability vector indicating how players should randomly pick a hero. Here for example is the 4th equilibrium computed by Sagemath:
sage:g.obtain_nash(algorithm='lrs')[3][(0,0,0,0,0,0,0,0,3947/17781,0,3194/17781,0,8795/17781,0,0,615/5927),(0,0,0,0,0,0,0,0,3947/17781,0,3194/17781,0,8795/17781,0,0,615/5927)]This particular equilibria has both players playing a mix of: Fortress, Glaive, Petal and Koshka.
Here is the mean probability distribution for both players, while the particular values should be ignored what is of interest is the heroes that are not played at all. In essence these heroes, accross all the equilibria are not deemed playable:

We see that this confirms how the previous graph was colored showing the heroes that should be played in blue.
Note that the number of guides and the reliability of all this has a huge effect of the conclusions made. Here are two gifs that show the effect of the number of guides used:
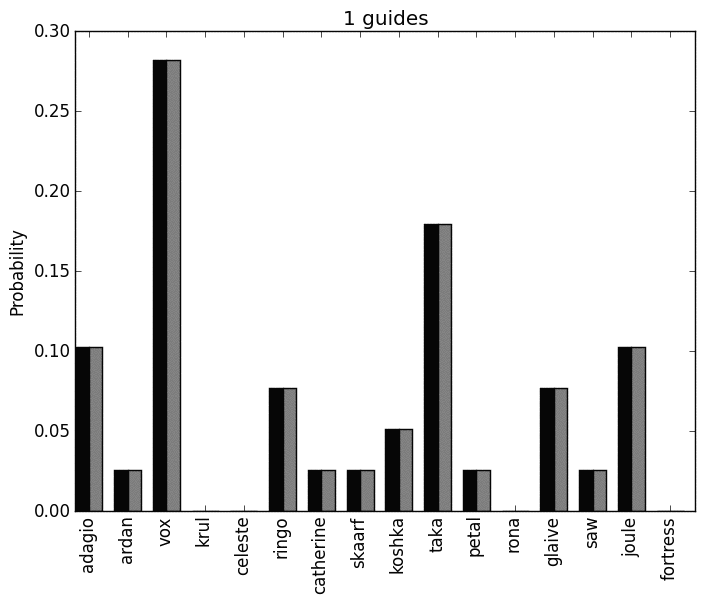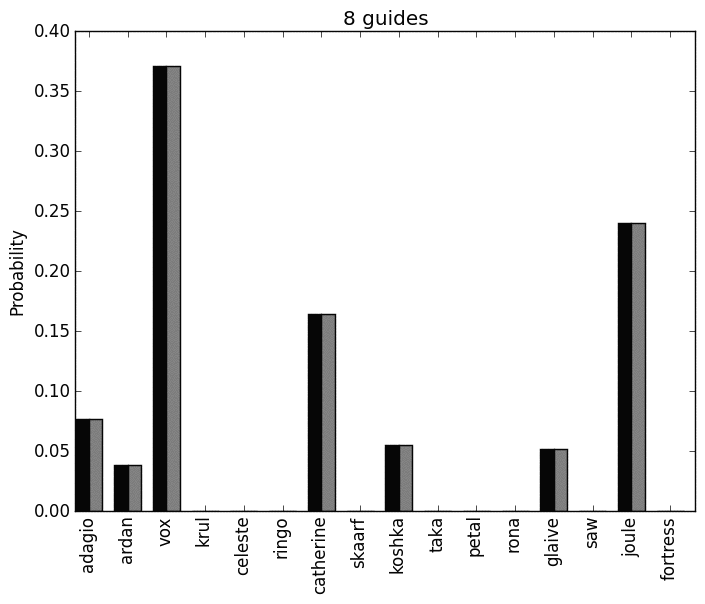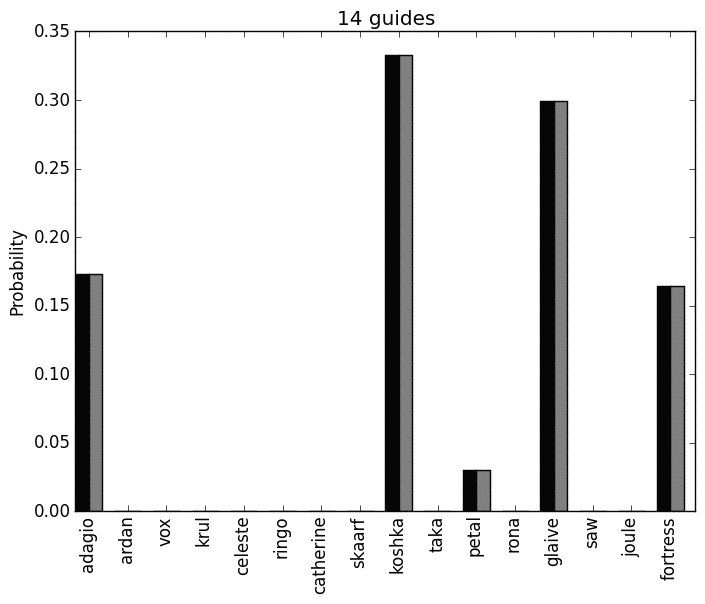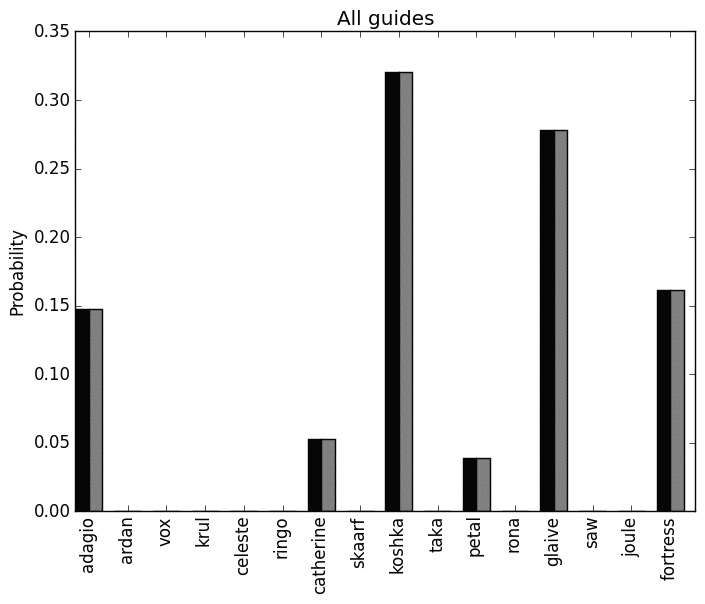
and here is a plot of the number of equilibria for each guide:

Up until now all the results are for when players aim to minimise the threat posed to them. In the next section I’ll invert that (python wise it’s a minor swapping around of some inputs) and consider the situation where you want to pick a hero that is aims to be the most threatening.
Seeking to be a threat
First of all here is the best response graph:

Here is the average of the NE:

Those 3 players have certainly been able to rip through me on more than one occasion…
Finally here are the Nash equilibria for when a threatening player (plotted in black) is playing against a threat averse player (plotted in grey):

Conclusion
The main thing that needs to be highlighted before concluding is that this analysis has two weaknesses:
- The data: what comes out of mathematical models is only as good as what goes in. Scraping the wiki data is a cool thing to do (from a Python point of view) but I’m blindly grabbing guides that might have poor information/opinions in them. This is worth remembering. If someone where to come up with their own threat/performance measures then this work could just be used on that. Ultimately the data available here is better than no data.
- I am not taking in to account team dynamics. I’m just looking at perceived threats from one hero to another. There are mathematical approaches that could be used to find the best combination of teams and I might get to that in other post one day. Nonetheless this has been a fun application of game theory and still has value I believe.
So to conclude, basing things on the data available to me, I’d suggest that (when both players are acting in a risk averse way) the choice of heros for an isolated job like jungling and/or laneing is in fact reduced to a set from:
If you and your opponent aim to be threatening, the choice is from:
Finally if you aim to be threatening, playing against a player aiming to be risk averse the choice is from:
and vice versa:
(Interestingly for this last type of game there were in general just 1 equilibrium.)
Based on all of this, I would suggest (looking across all of that summary) that (disclaimer: based on the wiki threat data) the bestVainglory hero is Glaive. Again though, this does not take in to account any of the very important team dynamics. I plan to keep on being a protector with Ardan and just doing my best to stay alive…
Another point is that this shows that vainglory is perhaps not immediately balanced. A perfectly balanced game (like Rock Paper Scissor for example) has a Nash Equilibria that evenly plays all strategies:
sage:g=game_theory.normal_form_games.RPS()sage:g.obtain_nash()[[(1/3,1/3,1/3),(1/3,1/3,1/3)]]Please do take a look at all the code/data at this repository.
This was a fun application of mathematical modelling, I also learnt how to scrape with BeautifulSoup but I mainly look forward to using this in my game theory class this year. I might even suggest we spend 25 minutes of one class having a game on the big screen assuming there are 5 players of Vainglory in my class.